This page is not created by, affiliated with, or supported by Slack Technologies, Inc.
2022-02-24
Channels
- # announcements (5)
- # aws (5)
- # aws-lambda (6)
- # babashka (6)
- # beginners (48)
- # calva (54)
- # clj-commons (12)
- # clj-kondo (39)
- # cljfx (3)
- # cljs-dev (11)
- # clojure (91)
- # clojure-europe (25)
- # clojure-uk (3)
- # clojurescript (16)
- # cursive (2)
- # data-oriented-programming (6)
- # datomic (8)
- # emacs (10)
- # events (3)
- # fulcro (2)
- # functionalprogramming (2)
- # graalvm (4)
- # graphql (2)
- # helix (1)
- # honeysql (4)
- # jobs (1)
- # malli (4)
- # nextjournal (21)
- # off-topic (5)
- # other-languages (4)
- # overtone (3)
- # reitit (17)
- # releases (2)
- # rewrite-clj (6)
- # ring (6)
- # shadow-cljs (37)
When dealing with, say an endpoint, is there a more elegant way to handle errors rather than a bunch of ugly nested if’s with a wedge of successful code at the top of the wedge and a matching stack of error handlers at the bottom?
I built a little thing recently playing around with doing this better, take a look! https://clojurians.slack.com/archives/C03RZGPG3/p1642025029110800
There's also fmnoise/flow https://github.com/fmnoise/flow Also farolero: https://github.com/IGJoshua/farolero
Very interesting stuff! I’ll take a look
Can you post an example of the currently painful code? I have a vanilla clojure pattern that might be handy
I'd be curious about said pattern
@U01EB0V3H39 Thanks for that very interesting write-up. You make some very good points in there, especially the note about monads. Without having used ex before, I actually started on something similar just last week. Now I don't have to! 🙂
I recently went looking for something that would allow me to add error handling to a multi-step process, where previous steps need to be undone if any step fails. Most of what I found came down to Railway Oriented Programming a la flow (the monadic approach). At the end of the day I settled for the Saga pattern (https://www.baeldung.com/wp-content/uploads/sites/4/2021/04/Figure-3-1536x954.png) with a layout very similar to the einter-> fn in @U01EB0V3H39's write-up.
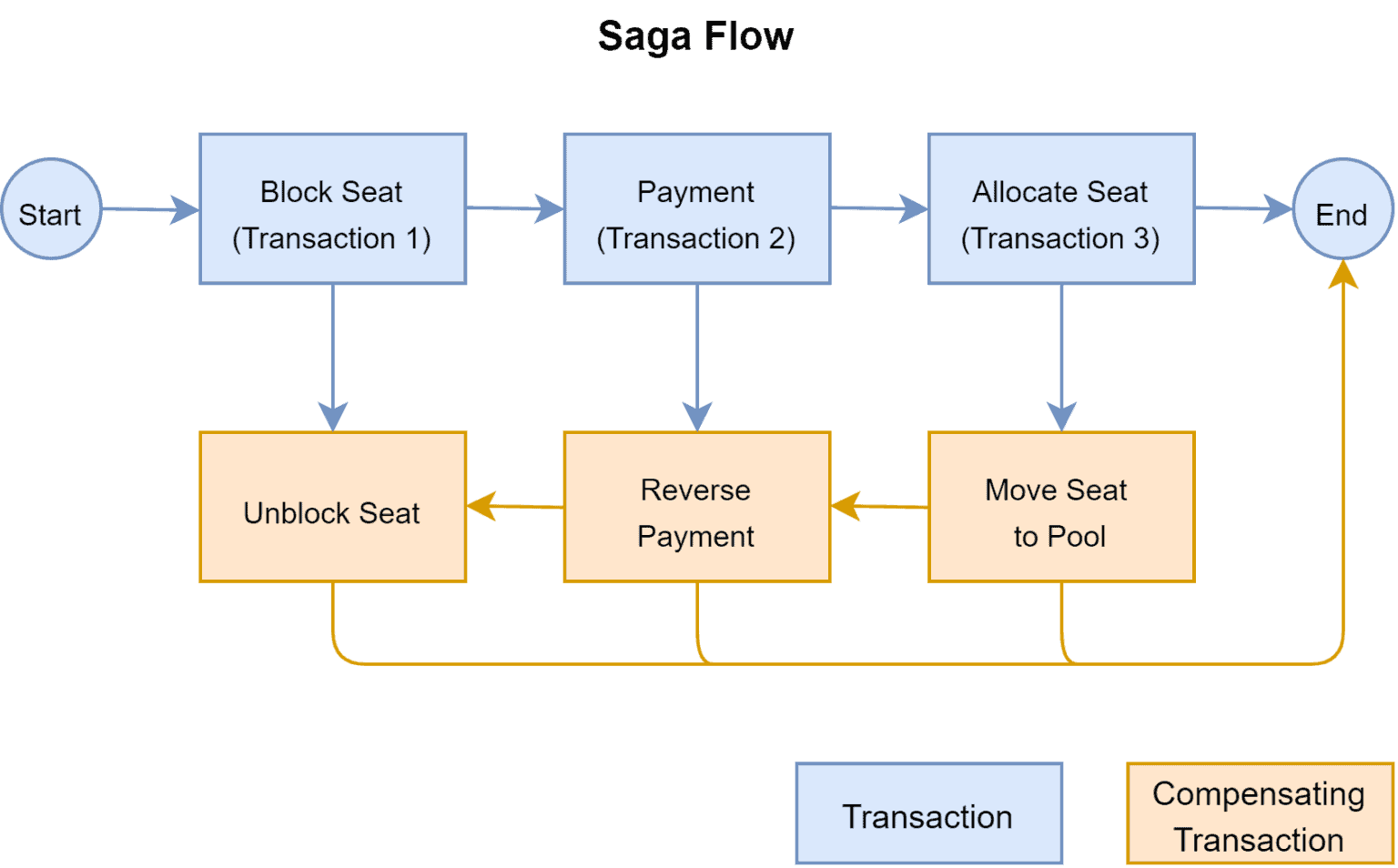{kind=link}
this looks like interceptors
I might be misreading that flow chart, but it looks a little like rather than returning early on errors, the saga pattern runs the full set of compensating transactions required to reverse the actions taken so far, which is a little different
@U01EB0V3H39 Yes, it's different. I just mentioned it as yet another approach for a different and specific use case. I don't think it's a good pattern for general error handling, or API error handling like in your scenario.
(defn tasks-url-hash [request]
(let [hash-id (get-in request [:path-params :hashid])]
(if-let [[task-id] (.decode hashid-instance hash-id)]
(if-let [[result] (db/update-task-complete! {:task_id task-id})]
(if (pos-int? (-> result first :next.jdbc/update-count))
(let [job (db/get-job-for-task {:task_id task-id})]
(response/found (:url job)))
(response/bad-request))
(response/bad-request))
(response/bad-request))))I feel like this particular case where many of the branches have the exact same thing you could just use nested when-let wrapped in an or
But if each branch has a different type of error that gets messy
So yeah fits perfectly with what I had in mind
(defn tasks-url-hash [request]
(let [hash-id (get-in request [:path-params :hashid])
[task-id] (.decode hashid-instance hash-id)]
(if-not task-id
(response/bad-request)
(let [[result] (db/update-task-complete! {:task_id task-id})]
(if-not result
(response/bad-request)
(if-not (pos-int? (-> result first :next.jdbc/update-count))
(response/bad-request)
(-> {:task_id task-id} db/get-job-for-task :url response/found)))))))(response/bad-request))
(response/bad-request))
(response/bad-request))cond or a better-cond (which I don't really cond-one ;p)@venv That reminds me of this use of guard clauses in Clojure:
(defn patuculator
[foo]
(when-not (valid? foo)
(throw (ex-info "Invalid foo" {:foo foo}))
(inc foo))I like both of those approaches! @U45T93RA6 I’ve been waffling back and forth on the guard clause approach because I like the ‘happy path’ to be the first one, but you’re right, that has ugly code consequences. @U5NCUG8NR I love the simplicity here when all ‘red paths’ have the same outcome, so I’ll try that as well.
I usually don’t have that many nested conditions, lol. And refactoring into functions seemed like overkill.
@UJY23QLS1 no, that doesn't violate the "exceptions as flow control" rule because if that exception is thrown it's programmer error, not user error. It's just assertions on the function's contract.
at least imo
This is distinct from like throwing an exception if there's an io failure or something else like that, which is exceptions as flow control because it's expected to happen in some cases regardless of if the programmer designed the program correctly.
when does something deserve to be a function?
e.g is this a good function?
(defn is-lovely? [person] (= :lovely (get-in person [:soul :who-they-are-on-the-inside] )))
I would say no, this function isn't really worth having because the caller basically has to know everything its doing, that is, you have to know that what your passing has those keys. I feel like i run into this kind of behavior quite often and i'm not sure if i'm just frustrated because "thingdevelopmentlife" is just hard and generally not really rewarding in the small or if this kind of thing is really a huge issue and i should start ranting about it the second i see it take hold.
I really want a function, that can take clj functions and just expand them down to clojure core functions. Like i dn't mind if someone wanted to create a bunch of wrapper functions, but i need a way to get a common ground of communication.
I don’t find your example particularly egregious tbh. However, I think I see what you’re getting after. I would often much rather have one, long function based on clojure core concepts rather than 7 layers deep of “whatever this person was thinking at the time” concepts.
Mostly because the common (read SOLID, read “Bob”) wisdom is that LoC == bad -> small fns == good -> more names == good. And those folks refuse to entertain the idea that names have a cost.
I hear you, i think my pain would be resolved if i could just quickly expand the functions tell i hit the layer i needed. I think if the fn only has one ref is just even under more scrutiny. It's not really a matter of naming, imo, but the lack of a clear abstraction. My example doesn't highlight that issue, I'm not sure how that's even possible. Like "lovely" is not a concept the computer can help me with. It deals with moving numbers around...
I mean, unless you actually trained a ml fn on pictures of things i found lovely.
> read SOLID, read “Bob”
😂
There is a cost to names, thank you! I had so many discussions about this...
As for the initial question that is really for you to decide. Looking at this implementation I would probably opt to have this be a function. When you change the rules on how to decide whether a person is lovely or not, you can then change this function and can leave other parts of the system alone.
If the part that makes decisions based on loveliness cares about how we derive this then you probably shouldn't use a function but I'd say most often in those places you wouldn't care and therefore shouldn't have it know the exact structure of person.
Right. We have to decide, but there needs to be some sense of how to judge. We're doing it all the time, i would be dismayed if we didn't have some intuition.
Fn Reuse itself isn't the goal, but synchronization. But even that by isn't a justification.
E.g (defn my-get [x] (get x))
Is clearly a mistake. It gives the caller nothing they didn't already have, less in fact, and it obsecures the underlying system.
The issue here is the cost isn't clear from my example. Is lovely isnt encapsulating anything. If tomorrow the lovely logic changes in anyway, all known callers will be broken. I mean, it's a call to get then equal, what is going to get refactored or optimized? (Yes i know get is slower then key look ups... Ignoring that)
Person has to be a hashmap with a specific known structure. The only thing it and it's fn like it are doing "hide" how it makes it's choices. I feel like this is the whole getters and setters argument rehashed. (see what i did there?)
Let me offer another option.
(Def the-inside [:soul :the-inside...])
Callers can safely reuse the path with get and call = :lovely. I can quickly use eval to bring this structure into my code because i know it has to be a vector. I can manipulate it using clojure.
I think the lesson here is one we have seen before.
Prefer data over code.
But why? Because callers know how to work with data and compose it. If you hand them functions, they have to learn your api ... And now you, the author, need to make that worth my time.
How do we get in the habit of preferring data?
maybe empathy.. maybe just experience.
Imagine learning clojure then visiting the code base you have created. Is learning it sparking joy? oh look, a sorting alg thats faster on numbers! Or is it dismay? Oh look twenty sorting functions... One for each kind of "person" type in our business domain... Was the author unaware of sort-by ??
I have no doubt i write code that will upset some future dev. Idk what to do about it but i think being self aware means it's far more likely I'll try to impose my belief system on a code base without high confidence and a well defined goal. Aka a library.
> The issue here is the cost isn't clear from my example. Is lovely isnt encapsulating anything. But it is! It is encapsulating the very structure of person. You can make it so that certain parts of the system need not be aware of that structure and I would argue that if they need not then they should not be aware.
> twenty sorting functions
I think I know what you mean, but there is a real difference between the following two
(sort-by #(= :lovely (get-in % [:soul :who-they-are-on-the-inside])) people)
and
(sort-by is-lovely? people)
I used to inline all such get-in functions in my code. I had since regretted that decision and am gradually rewriting that so there proprly named functions.
@U07S8JGF7 Bob is now a Clojure fan, so expect all your Bob'isms to come to Clojure soon 😄 I've already seen his live streams doing clojure, it's Clojure, but not as you know it 😄
@U013YN3T4DA yeah! I still can't wrap my head around this one. I didn't know about the live streams, I have to check those out. I watched a talk from him from 2020 where he proposed that we all should stop it with those different programming languages and all use Clojure instead. This was a pretty fun talk
@U01DV4FGYJ0 your saying it's encapsulation but not addressing my comments about that. I'm saying every part of the system is aware of the structure, they %100 know they have to pass a map. Why those exact keys
Imagine i just handed you the fn but didn't give you a way to look at the body. Imagine writing the doc string for it, what would you have to say?
Would it be more or less words than the code itself? I don't think it would. I'll rewatch erics talk, but I recall thinking, yea, this is because hashmaps aren't the right data structure for most business domain relationships. That's why we have sql and datalog.
@U013YN3T4DA I’ve noticed it since the beginning. As people began to move to clojure, they bring all their SOLIDisms with them—which is to be expected. My irritation is the utter lack of awareness of the costs.
In this case, if i could expand the function tell everything visible is just a clojure core function, i think i would be able to just ignore 90% of the cost. Which i think might actually tip things in favor of writing things this way.
I did that to a section of code i found recently, i pulled in 100+ lines of code. I refactored it to 3 to 5 in about ten minutes. That's the tradeoff, you lose the ability to see the forest through the trees.
> That's why we have sql and datalog. Aren't query languages completely orthogonal to data structures?
Exactly, I've brought that up here before. That we write walls and walls of code and you can't see the forest for the trees. It came up the other day actually, on a call with my boss, he said that the problem is I want to write simple code, and for others that just isn't really a priority... Like this was a criticism. I was quite shocked that he said that and didn't realise the absurdity of what he was saying. A lot of our issues where we write mega amounts of code I think falls to a few things. 1. People are far too far behind with current technology, so everything is basically if statements and for loops, they aren't aware of the newer features in languages we use. 2. NO idea about data structures. YOu need more of one thing, it's a list! Forget dictionaries, sets, trees etc. All you need is a list. 3. Their code is a stream of conciousness, I need to do something to each one, I'll write a loop, now I need to decide something, I'll write an if statement. Oh I forgot something I should have done before the loop, I'll just stick a function call in here.... Then there are functions that aren't called, as they've changed their mind mid coding. Some of it you can visibly see the train of thought they were jumping around in, and piece in the functions they orginally called then removed the calls... Honestly, its a complete stream of conciousness.
Your domain has concerns. When that concern is get-username, it's all clear. When that concern is (get-in db [:users id :username]), it's incredibly less clear. And it becomes a huge PITA when you decide that your db structure now has to be slightly different.
I'm not saying you should replace all get-in calls with extracted methods. I'm saying that you should separate wheat from chaff in a reasonable manner. You shouldn't put everything in your pot, neither should you throw everything out.
+1 for extracting is-lovely? into a fn, if only for the reason that it'll make the calling code easier to read and understand (as @U01DV4FGYJ0 https://clojurians.slack.com/archives/C03S1KBA2/p1645693758187019?thread_ts=1645669684.387309&cid=C03S1KBA2)... if it's well named. Naming is hard and a bad name may reduce readability/comprehension of calling code.
yea but i generally don't have to read code unless i have to fix it or extend it, is-lovely? doesn't help with either. At least upon introduction 😆
If we assume that code is more often read than written, someone else working on the same code base might just need to understand the code in passing, and need not necessarily fix/extend it. In that (common) case I think @U01DV4FGYJ0's example is very illustrative. Unless of course the code won't be seen by anyone else, then it's really only your own preference that counts. 🙂
Maybe I should rather put it this way, if I had to read code sorting people by loveliness, (sort-by is-lovely? ...) would read significantly easier to me.
i speak fluent clojure core, "is-lovely?" is like saying "falborcotas novaka?" (some foreign language)
I'm likely a lot less fluent in core, but there's still less parsing and mental interpretation needed with is-lovely?. I don't need to know how loveliness is determined, so I can just focus on what the calling fn is doing.
I feel were agreeing in a round about way, your saying the name seems to carry a more human readable narrative, i'm saying in the case where i have to read that function, it's likely that narrative is misleading. Or have to fundamental change it.
Ah, I think I missed the "where I have to read that function" part. Yes, I think we agree. The fn adds some cost to changing the function, but reduces cost in reading usage (callers) of it. Assuming the latter happens disproportionately more often, I tend to optimize for it.
I also go back and forth about where the line is to be drawn, though. As you've also correctly stated, my-get is useless.
@U0DJ4T5U1 sorry for the late reply
> Person has to be a hashmap with a specific known structure
I think knowing about something is key here. When is-lovely? is a function we only know and concern ourselves with the fact that a person can be lovely or not. When we say (get-in person [:soul :who-they-are-on-the-inside]) then we know this but also that a person has a soul. The less certain parts know about each other the less coupled they are.
Here I would imagine that there was a namespace containing only such functions operating on person maps. Other namespaces only refer to the functions they need and therefore need less assumptions and at the same time make it clear on which part of the map they depend.
It's a lot about separating "what" from "how". Actually "encapsulation" really seems to be the wrong idea here, you are right.
> (defn my-get [x] (get x))
Harmful and useless function indeed
> Imagine i just handed you the fn but didn't give you a way to look at the body. Imagine writing the doc string for it, what would you have to say?
Ideally in the place where you were using the function you wouldn't care about the body, I think. The name in this particular case hints at a lot, maybe a docstring is not needed.
> Eric Normand
I'd like to second that. I don't know this talk but I've read through parts of his book "Grokking Simplicity", and he does a great job of discussing things like those with good examples.
> Right now, I’m assuming the triviality of your example is getting in the way here 🙂
It would be great to discuss this over real world problems indeed!
I just thought about another thing, I think I originally have this from good ol' Uncle Bob 😬 - stuff that changes together belongs together. If you group data access to person maps then changes to the structure of the map really only affect one namespace.
May I offer this as a real-world example? https://gist.github.com/walterl/f6642e0f7f2e97078befe317f4c36aee
@U01DV4FGYJ0 , the caller knows a person has a soul. They passed a map that says exactly that. That's my point about the docs, without them, no one will ever use this function without first going read the fn body. In a real code base you would end up with a mix of calls that just used clojure get and likely at least two versions of "is lovely" because getting values from hashmaps is like breathing, i dont even think about it. The only advantage here is synchronization, if we change how a person is structured, we only have to change this function. But that's a gamble, if we change person, maybe we don't need this at all? Keep in mind my whole argument here is that its hard to change structure that's hidden~encapsulated. That's the artistic element here, knowing how useful your abstraction is as a writer gives you insight into how ridgid you can make it. The more you give your users, the more they can focus on there specific problem, the more likely this kind of rigidity can help. I imagine your thinking of some really great library, I'm taking about one off application code thats littered around. We seem to be claiming that "is-lovely" is easier on the reader, but that's contextual, if the reader is having to fix a problem in this code then they are opening up it's guts, and that means the abstraction is broken. The api is degraded, they can't trust the story. They have to reach for a common ground of communication. I think a need for certenty can push us to view design curves as linear, but that makes us brittle. I think some of my woes stem from not being able to quickly read the code. I'm working in cljs and it has less tooling. I heard you can debug using the chrome, but I'm guessing that steps through the JavaScript. You can capture vars, but that's slow. I think a proper debugger and a way to expand a clojure tell i only have core functions would mean i could quickly step past or unwrap the fn name that broke my expectation.
Ah, shame. Because I really dislike having to click on the existing Clojars badges just so I can select the text.
I didn't mean specifically Reveal. All I meant is that people often put an easy-to-embed badge in their repors, but that badge ends up being an image and it's not selectable, so getting coordinates for the latest release requires more actions than needed.
And I understand that it's likely a GitHub issue and not a problem that's supposed to be solved by separate maintainers in separate repositories.
Does anyone know of any clojure tools that will take a json schema and convert it into a property based test of some sort? Preferably by targeting clojure.spec / plumatic schema or malli?
I believe this is planned for malli.
I’ve found an implementation of something similar in martian; via martian.schema/make-schema and schema-generators; however that appears to target swagger/openapi which I believe is subtly different to json schema
I have two questions regarding the new parse-double and parse-long functions that are coming as part of Clojure 1.11 1. These functions follow nil-punning practices, but if they are passed `nil`, they throw an error. What’s the rationale for throwing an error instead of just returning nil? 2. What was the reason for having `parse-double` and `parse-long` but not `parse-float` or `parse-int` as well?
re: double and long but not float and int, clojure general prefers the 64bit values. when read 1 is a long, not an int, 1.0 is a double, not a float, primitive functions only support long and double primitive arguments, etc
For the second thing, that makes sense. Thanks for the explanation.
For the first thing, I read that thread and I understand that passing nil to these functions is undefined, but I’m mostly curious as to why it’s undefined? Why not just return nil ?
there has been a fair bit of virtual ink spilled in #clojure-dev and elsewhere about the parse functions, but I don't think I've seen alex go into that level detail, basically just "why is it like x?" "because it is spec'ed like y, which allows for x"
even the jira ticket while listing different possible behaviors, doesn't provide rationales for the chosen behaviors
they are functions that define behavior over strings
nil is not a string
part of the trickiness of this kind of thing is once you dig deep in, it exposes the potential for endless bikeshedding
so I think there is some reluctance to open that discussion, so instead you just get "it is the way it is because it is defined to be the way it is"
we talked about it at length and decided that nil is not a valid input to these functions
I did look at a lot of existing code using the JDK parse functions. in many cases your input is from a user field or a command line value where you always have a string. if you may have nil, you are a (some-> val parse-long) away
(Long/parseLong nil) is going to throw too (that's all we're surfacing)
so in summary as to why: nil is not a valid input
Got it. Thanks for the details on all of this.
> part of the trickiness of this kind of thing is once you dig deep in, it exposes the potential for endless bikeshedding
>
> so I think there is some reluctance to open that discussion, so instead you just get “it is the way it is because it is defined to be the way it is”
To be clear, I wasn’t complaining or even suggesting it should be changed. I was just curious for the rationale behind it all. I commonly find myself writing numeric parsing functions in a lot of my projects that wrap the Java versions of these functions. So the addition of parse-double and parse-long certainly saves me some trouble. I can now swap these out to just use (some-> val parse-long) as mentioned above which is what I’ll end up doing.
Thank you!