Clojurians Log v2
observability

@bruno.bonacci is it possible to use mulog to capture the logs from an embedded jetty server that runs my web application (reitit, ring). Or would a more typical java logger to capture the jetty logs and push them to the same log service as mulog
Ah, it seems I would just send both sources to something like elastic search and that would merge the two sources.

Yeah I too am curious what the ideal way is to manage structured logging in the face of existing less structured stuff

Hi @jr0cket, yes μ/log can do that. with a single well crafted ring wrapper you can callect enough information to perform a large number of queries (see [comment](https://github.com/BrunoBonacci/mulog/issues/25#issuecomment-656062331))
this was one of the main design goals of μ/log.
here there is a [simple wrapper example](https://github.com/BrunoBonacci/mulog/blob/master/examples/roads-disruptions/src/com/brunobonacci/disruptions/api.clj#L56-L69) This works, not only on a single application, but if you are in a microservice environment, and each system instruments with a fairly simple wrapper you can get tracing across all your application without the need of expensive tooling and you still get to keep the raw data.
μ/trace captures the relationship of internal calls to other μ/trace as well generating call traces like https://raw.githubusercontent.com/BrunoBonacci/mulog/master/examples/roads-disruptions/doc/images/disruption-trace.png
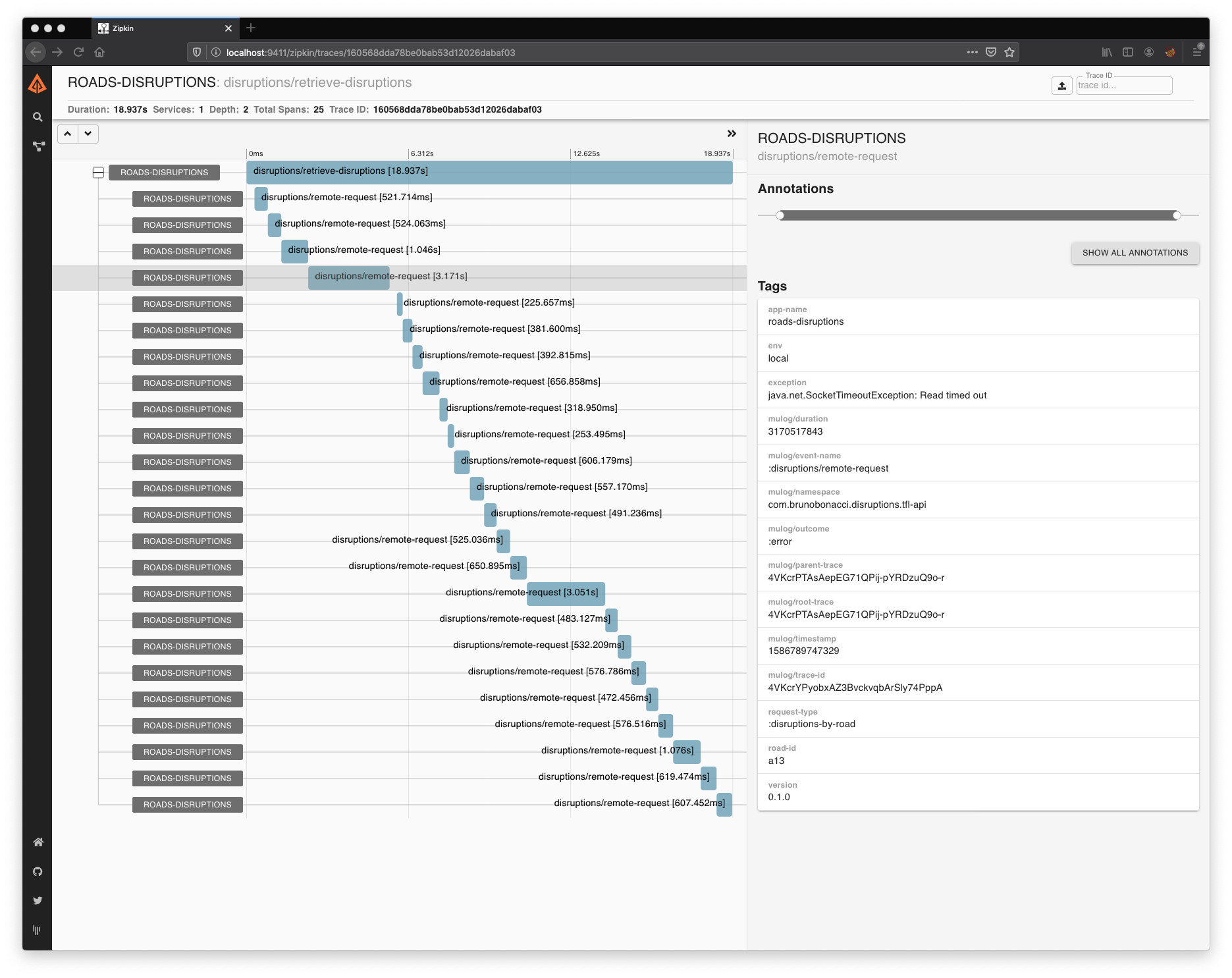{kind=link}
There are teams that use it to build complex pipelines to detect quite sophisticate issues in their systems μ/log -> kafka -> streaming-app -> kafka -> monitoring-dashboard and it is just the same data that they already use with Elasticsearch or Cloudwatch
(at some point) I hope to make a talk about how teams use μ/log for observability and operation (autoscaling, downscaling, warm-up, etc)
seeing all this in practice makes so much more sense.
Excellent, thank you. I will start adopting mulog on all our new Clojure projects and look for opportunities to adopt on existing projects