Clojurians Log v2
polylith 2024-06-11

Hi there,
I've read what I can find about profiles but I still get an error when running poly info +mock
Error 107: Missing components in the development project for these interfaces: psql
I have two profiles :+default and :+mock , where mock has the psql-fake -component and default has the psql-component. Both have the same interface-nses but different implementation-nses. (`de.yobst.psql-fake.core` and de.yobst.psql.core respectively). So obviously the mock-profile does not have psql-component. But it should not throw an error. What am I doing wrong?
Do you then name both namespaces for the impl de.yobst.psql.core? Or would you avoid having both named the same? I am getting a redefined-var from kondo now

Yes, all my impl nses have the same name (I use impl rather than core but that doesn't matter). No idea why you'd see redefined var from kondo...
Show your :+mock and :+default aliases.
So you have components/psql/src/de/yobst/psql/interface.clj with de.yobst.psql.interface and components/psql-fake/src/de/yobst/psql/interface.clj with de.yobst.psql.interface`, yes?
And your :dev alias has neither brick, but :+default has :extra-deps {.. {:local/root "components/psql"}} and your :+mock has :extra-deps {.. {:local/root "components/psql-fake"}} yes?

If you export the workspace with e.g. poly ws out:timo.edn and send it to me, then I will have a look @timok.
Thanks @seancorfield, that's exactly what I was missing... I had the components/psql-fake/src/de/yobst/psql_fake/interface.clj with the namespace de.yobst.psql.interface and suppressed the kondo-warning

Hi, I am a novice with Polylith, but I plan to start using it seriously. I anticipate creating numerous components and think it would be advantageous to organize them by grouping by name or another method, to easily capture the nature of the components. What are the best practices for this approach? Alternatively, does the Polylith philosophy discourage such structuring methods like grouping and/or layering in general? Any advice would be greatly appreciated.

I ended up creating components called database and database-postgres where I put all the postgres customization's for things like jsonb fields, then database uses that component my thinking was that if I ever want to change databases I can create a new component database-mysql for example and switch the deps used in database component.
Sounds reasonable to me, but I have no experience with this specific use case.
Thank you all for your input. Using prefixes to clarify the nature of the components might be sufficient for my case. The idea of switching deps is also helpful. This approach isn't limited to database components; when there is an implicit hierarchy, the degree of generality of the component used as the representative might require some judgement (next.jdbc seems to be a good standard in this regard).
One of the things that we found beneficial about Polylith was that, specifically because the components space is "flat", you start to think a lot more about naming and also single responsibility.
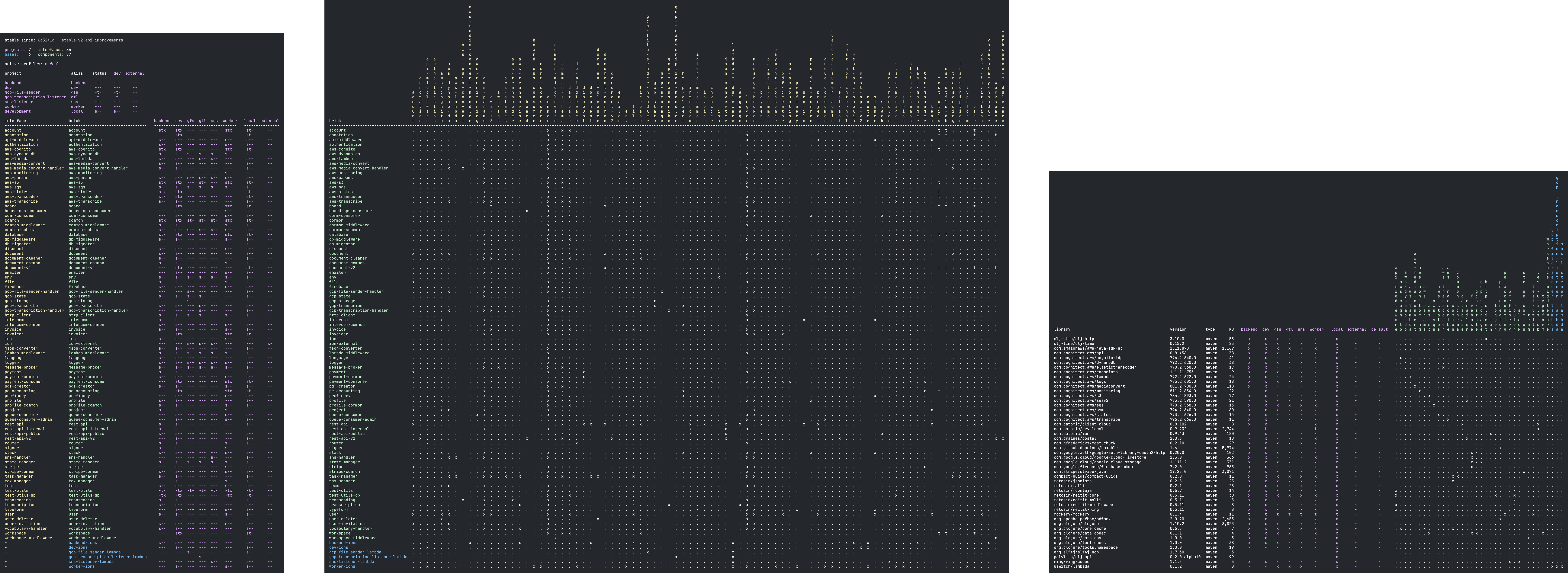
We've gone for fairly granular components for the most part and we have over 150 of them at this point:
projects: 23 interfaces: 161
bases: 23 components: 163 Polylith:
23 bases 454 files 75263 total loc,
163 components 795 files 69893 total loc,
23 projects 7 files 625 total loc,
total 1256 files 145781 total loc.We have very few "prefixed" names in our components.
We often separate out readonly/query logic from insert-update/command logic and have two separate components, so we have feature-flags and feature-flags-admin for example, or query-shared-photo and command-shared-photo (we have a few query-* and command-* pairs).
I was impressed by the thoroughness in separating readonly/query logic from insert-update/command logic into different components. The naming method of feature-flags is also a useful reference for me. The concept of single responsibility in Polylith is appealing, and I aim to code accordingly (while it seems quite challenging due to its depth). I recall the reason for wanting to group components: listing numerous components becomes less clear. While I haven't fully mastered the poly commands yet, I think it might be convenient if a component could have meta information consisting of keywords like :query, :command, :admin or :photo to specify its features so that a poly command could list only the relevant components when a keyword is given to the command. This simple idea might have already been discussed, though.
TBH, I don't find poly info very useful, because it's just easier to use my editor features to navigate a repo of our size (VS Code/Calva).
As for metadata, I don't know where you'd store that since you're really talking about filesystem entities... I guess you could add metadata to namespaces but that seems a bit error-prone since it would be detached from the component name which is really the key thing here, IMO, because the name exists for everyone working on the codebase, whereas metadata is really only useful to tools, or requires devs to open a file to see what it is annotated with.

To my understanding, the "component hierarchy" should ultimately be flat, as in, no real layering/grouping. Components can require other components, so maybe a hierarchy could form from there, but components should not be bidirectionally intertwined with other components. There shouldn't be any real "inheritance" between components.
For example: you might have a mysql component, which wraps some generic mysql-database functions (querying, inserting, connecting, etc), but that could reference a config component which has some generic config-file-reading/parsing functions.
Components should have well-defined (and ideally small) boundaries, like the proverbial lego block :^)
Thank you for your prompt response. I understand that we should avoid components being intertwined in a bidirectional manner. For example, if there are several database-related components like a mysql component and a postgres component, I thought grouping them could be effective in showing that they have similar functionalities. But, would naming them something like db_mysql and db_postgres be the best we can do?
(mildly nitpicky, but I don't think the db_ is necessary, that itself implies a hierarchy/higher-domain). And so, I think having a unified database component (as in, not mysql or psql specific), that abstracts operations (inserts, etc) across databases could be useful/convenient, and I have done the thought experiment on how to build it, but eventually I just realized that I was just planning how to build next.jdbc (a much worse version, at least).
As im thinking about it, I guess you could make a component that just exports next.jdbc functions, but you're not really gaining any abstraction benefits from that. I will describe my mysql component a little though, to maybe hint at where it sits abstraction-wise. It does provide some generic insert/delete/select/connection functions. In addition to that core mysql.interface namespace, I also have a mysql.interface.<dbX> namespace that reads a config file and exposes a ds function, which is a connection to dbX. I don't have any canned queries, however, I will add that those generic querying functions are wrapped so that they expect honeysql maps, rather than raw sql.
You can get some inspiration from other production systems, e.g. https://raw.githubusercontent.com/polyfy/polylith/v0.2.19/doc/images/production-systems/scrintal.png. If you zoom in, you will see that they sometimes group their components with a prefix, and sometimes not.
{kind=link}